Дано: есть веб-страница с сайта, с которого нельзя скопировать текст (он не выделяется). Задача: перевести информацию в текстовый документ. Вот такую проблему мне пришлось решать на днях. На все про все у меня было не больше 10 минут.
Меня попросили скопировать информацию с нескольких страниц сайта Бессмертный полк. Все страницы защищены: выделить текст у вас не получится. Но можно найти обходной путь. Показываю способ на примере этой страницы: http://moypolk.ru/rekomendacii-po-poisku.
Сначала можно попробовать открыть исходный код веб-страницы в браузере (Ctrl+U). На некоторых сайтах текст отсюда копируется легко. Но тут используется очень много html-тегов, так что не вариант.
Еще можно сделать скриншоты страницы и прогнать их через онлайн-распознавалки текстов. Но если страница длинная, это долго и требует много лишних движений.

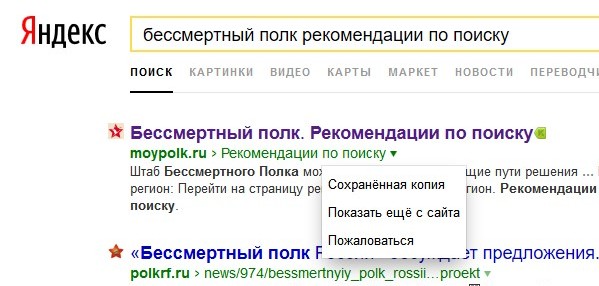
Тут я вспомнил про Яндекс. В поисковой строке написал название сайта (можно написать адрес, можно общеизвестное название — в моем случае, Бессмертный полк) и добавил несколько слов с нужной страницы.
В поиске эта страница вылезла первой. Переходить на нее нет смысла. Нужно щелкнуть по перевернутому треугольнику под названием страницы и выбрать «Сохраненная копия».
Откроется сохраненная копия страницы. Если текст по-прежнему не выделяется, выберите опцию «Посмотреть текстовую копию». Теперь вы сможете без проблем выделить нужный вам текст.
