Сегодня мы посмотрим, как справляются с распознаванием текста популярные и бесплатные интернет-сервисы. В качестве тестового изображения мы использовали скриншот части статьи про Москву из Википедии.
https://convertio.co/ru/ocr/
Без регистрации доступно распознавание 10 страниц. Поддерживается большое число форматов изображений, а также PDF. Также вы можете загрузить многостраничный PDF-документ или ZIP-архив с отсканированными картинками. Файлы можно загружать с компьютера, Dropbox, Google Drive или указать интернет-ссылку.
Готовый результат можно сохранить в один 11 доступных форматов.
Результат сканирования: 4 (хорошо). Не распознаны сноски и некоторые знаки препинания.

https://img2txt.com/
Поддерживается только четыре формата: jpg, jpeg, png, bmp. Максимальный размер файла — 4 Мб. Перед тем как вывести результат, Firefox просит у меня заново отобразить страницу. Это, конечно, раздражает. Готовый результат представяется в виде текста в окне веб-страницы.
Результат сканирования: 2 (неудовлетворительно). После работы этого сервиса придется исправлять огромное количество ошибок и опечаток. Быстрее набрать текст вручную.

https://finereaderonline.com/ru-ru
Это сервис от признанного лидера в сфере OCR — компании ABBYY, известной своим приложением FineReader. Вы можете загрузить изображение размером не более 100 Мб (PDF не поддерживается, но PDF можно легко превратить в картинки).
Сохранить распознанный текст можно в один из девяти распространенных форматов или экспортировать Dropbox, Google Drive и другие.
На сайте указано, что бесплатно можно распознавать до 5 страниц в месяц. Но у меня получилось это сделать только после регистрации и подтверждения e-mail: были предоставлены 10 страниц на 15 дней.
Результат сканирования: 4+ (хорошо). Не распознаны сноски и некоторые знаки препинания. Ошибок чуть меньше, чем у первого сервиса.

https://www.onlineocr.net/
Еще один бесплатный сервис. Принимает PDF и четыре популярных типа изображений (JPG, BMP, TIFF, GIF). Текст можно сохранить в трех форматах. После регистрации появятся расширенные возможности (многостраничный PDF, архив изображений и т.п.).
Результат сканирования: 5- (отлично). Самый лучший результат среди всех: сноски распознаны.
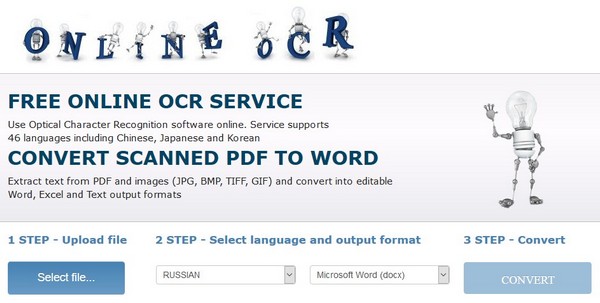

http://www.i2ocr.com/
Сервис поддерживает более 60 языков (впрочем, нам обычно нужен только русский).
Результат распознавания: 3 (удовлетворительно). Много ошибок, но не так много, как у второго претендента.

Выводы
Учтите, мы использовали очень легкий для распознования тестовый документ. Если у вас отсканированное изображение, нужно его улучшить: перевести в черно-белый формат, добавить яркости и контрастности и т.п. Но главное — удалось выяснить, что если вам нужно распознать небольшой объем текста, можно смело пользоваться интернет-сервисами.